Vertrauensintervalle (Konfidenzintervalle)
16.10.2022Einstiegsbeispiel: Wahlergebnis
Für die Kommunalwahl am kommenden Sonntag hat eine kandidierende Partei eine Umfrage durchgeführt. Dabei wurden 1000 Personen befragt und 373 gaben an, diese Partei zu wählen. Die Frage ist, mit wie viel Prozent der Stimmen die Partei bei der Wahl rechnen kann. Als wahrscheinlichsten Wert würde man annehmen, da dies genau der relativen Häufigkeit aus der Umfrage entspricht. (Dies nennt man eine Punktschätzung ) Genauer betrachtet sucht man eine unbekannte Wahrscheinlichkeit , hier das Wahlergebnis am Sonntag. In der Praxis gibt man gerne ein Intervall an, in dem der Schätzwert (hier das Umfrageergebnis) mit hoher Wahrscheinlichkeit liegt, ein sogenanntes Vertrauensintervall oder auch Konfidenzintervall genannt. Ein gängiger Wert ist das 95%-Vertrauensintervall , das Intervall für , in dem der Schätzwert mit -iger Wahrscheinlichkeit liegt.
Die Sigma-Regel sagt uns, dass die beobachtete Trefferzahl (hier 373) mit 95%-iger Wahrscheinlichkeit im Intervall
\[ [ \mu - 1{,}96 \cdot\sigma \quad; \quad\mu + 1{,}96 \cdot\sigma ] \]
liegt. Durch einige Umformungen und Näherungen, die ich später einfügen werde, erhält man als Näherungswert für das Vertrauensintervall:
\[ \tiny h - 1{,}96\cdot\sqrt{\frac{h\cdot(1-h)}{n}} \quad \le \quad p \quad \le \quad h + 1{,}96\cdot\sqrt{\frac{h\cdot(1-h)}{n}} \]
Für das Beispiel ergibt sich somit, dass die Partei bei der Wahl am Sonntag mit einer Wahrscheinlichkeit von 95% zwischen 34,3% und 40,3% erhält.
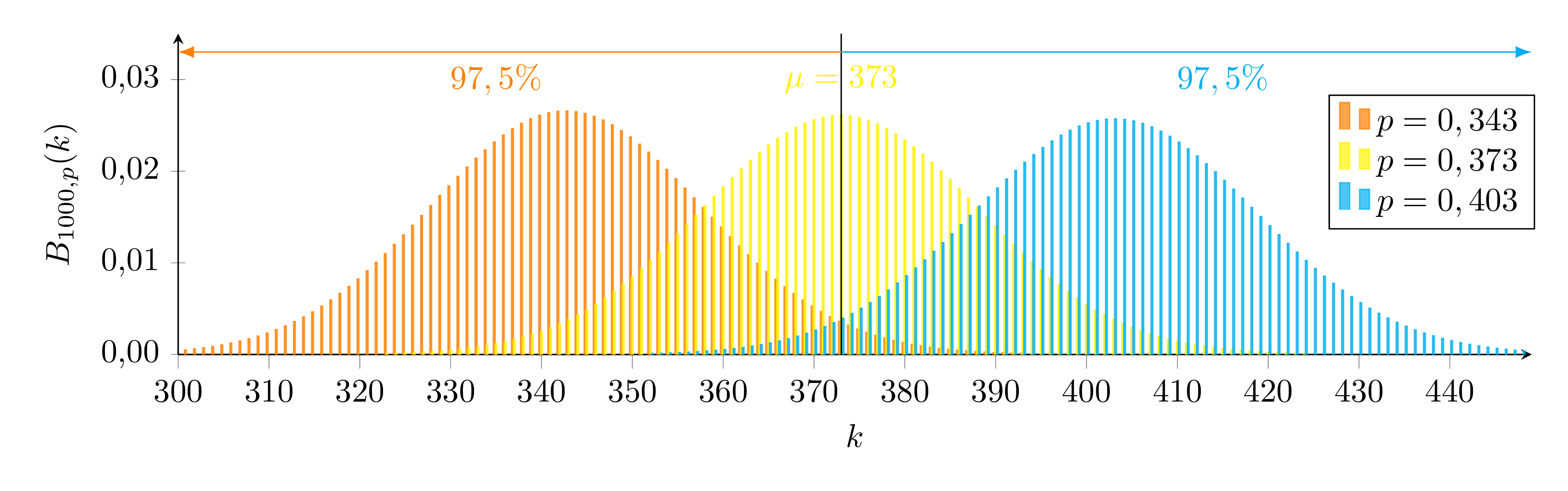 Grafisch bedeutet dies, dass der Schätzwert 373 gerade außerhalb des 97,5%-Bereichs der orangenen Verteilung und gerade unterhalb des 2,5%-Bereichs der blauen Verteilung liegt.
Grafisch bedeutet dies, dass der Schätzwert 373 gerade außerhalb des 97,5%-Bereichs der orangenen Verteilung und gerade unterhalb des 2,5%-Bereichs der blauen Verteilung liegt.
Exakt bestimmen kann man dieses Intervall so:
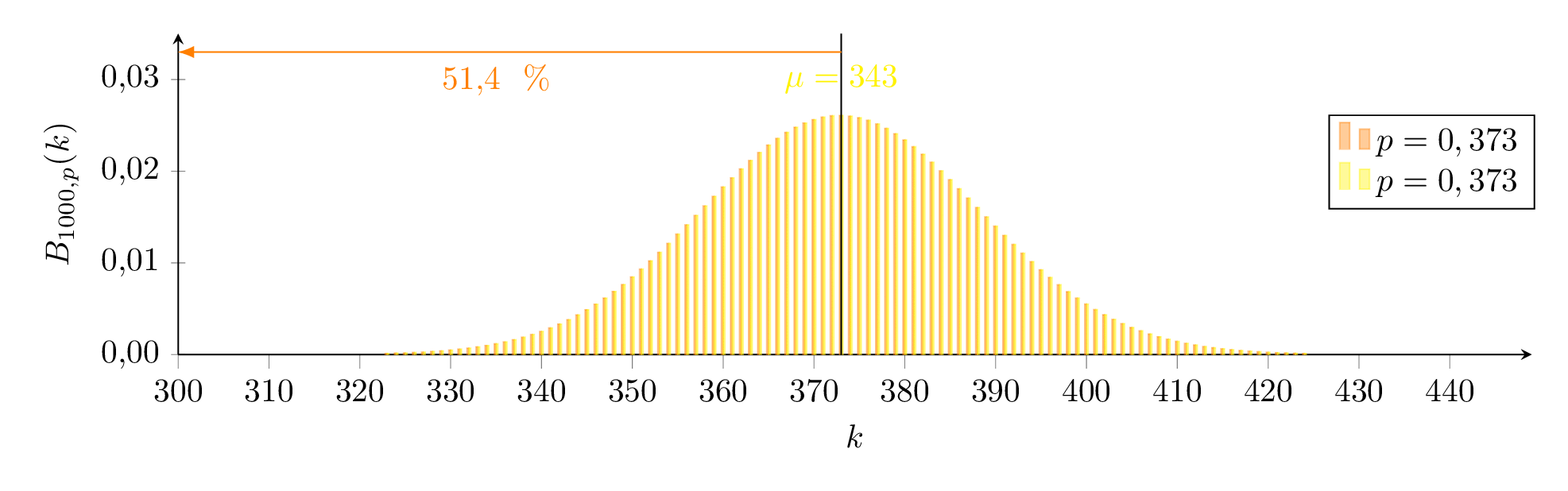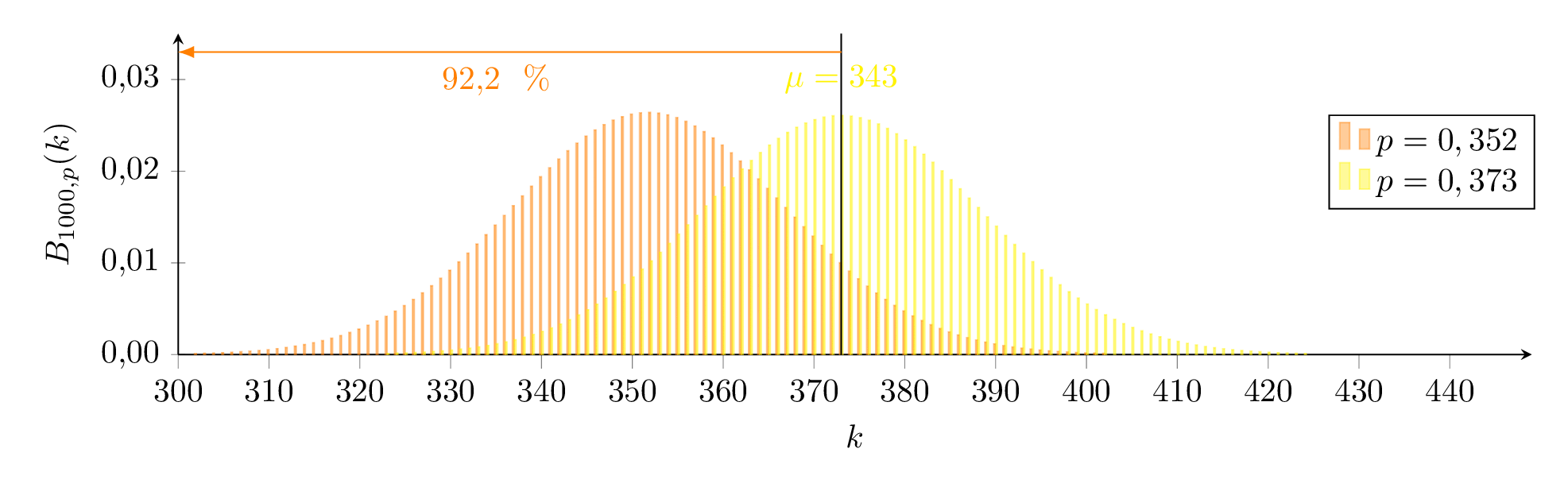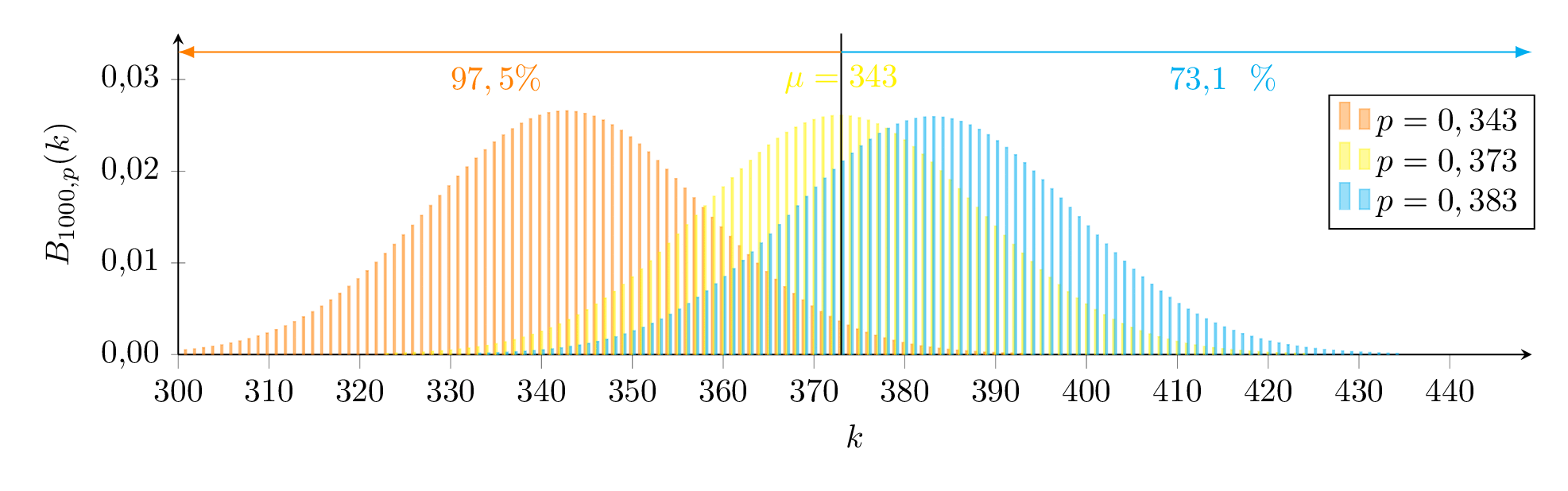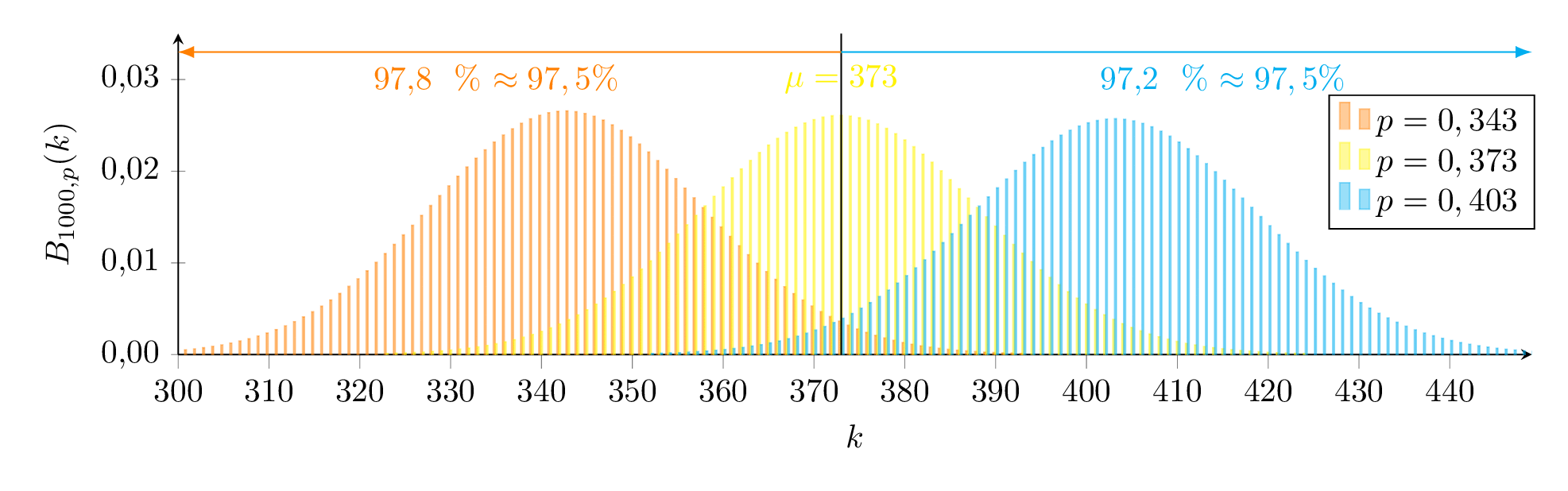 Wir suchen also eine Binomialverteilung für die Untergrenze (orange) so, dass gilt und eine für die Obergrenze (blau) so, dass gilt.
Da man die Formel für die kummulierte Wahrscheinlichkeit bei der Binomialverteilung nicht nach auflösen kann, muss man sich mit dem Taschenrechner (oder dem Computer) durch gezieltes Ausprobieren diesen Werten nähern.
Wir suchen also eine Binomialverteilung für die Untergrenze (orange) so, dass gilt und eine für die Obergrenze (blau) so, dass gilt.
Da man die Formel für die kummulierte Wahrscheinlichkeit bei der Binomialverteilung nicht nach auflösen kann, muss man sich mit dem Taschenrechner (oder dem Computer) durch gezieltes Ausprobieren diesen Werten nähern.
Wir sind mit unserem Forschungsschiff auf einer abgelegenen Südseeinsel gelandet, die von einer eingeführten Kaninchenpopulation beherrscht wird. Wir wollen abschätzen, wie viele der Tiere die Insel bevölkern. Dazu fangen wir 50 Kaninchen, markieren sie und lassen sie wieder laufen, in der Hoffnung, dass diese sich gleichmäßig über der Insel verteilen. Einige Tage später fangen wir erneut 50 Kaninchen und zählen darunter 18 markierte Individuen.
Nun wollen wir mit Hilfe des -Konfidenzintervalls für die beobachtete relative Häufigkeit der markierten Kaninchen abschätzen, wie groß die Kaninchenpopulation ist.
Lösung:
Als erste Schätzung gehen wir davon aus, dass unsere beobachtete relative Häufigkeit der Wahrscheinlichkeit entspricht. Dies würde zu Kaninchen führen.
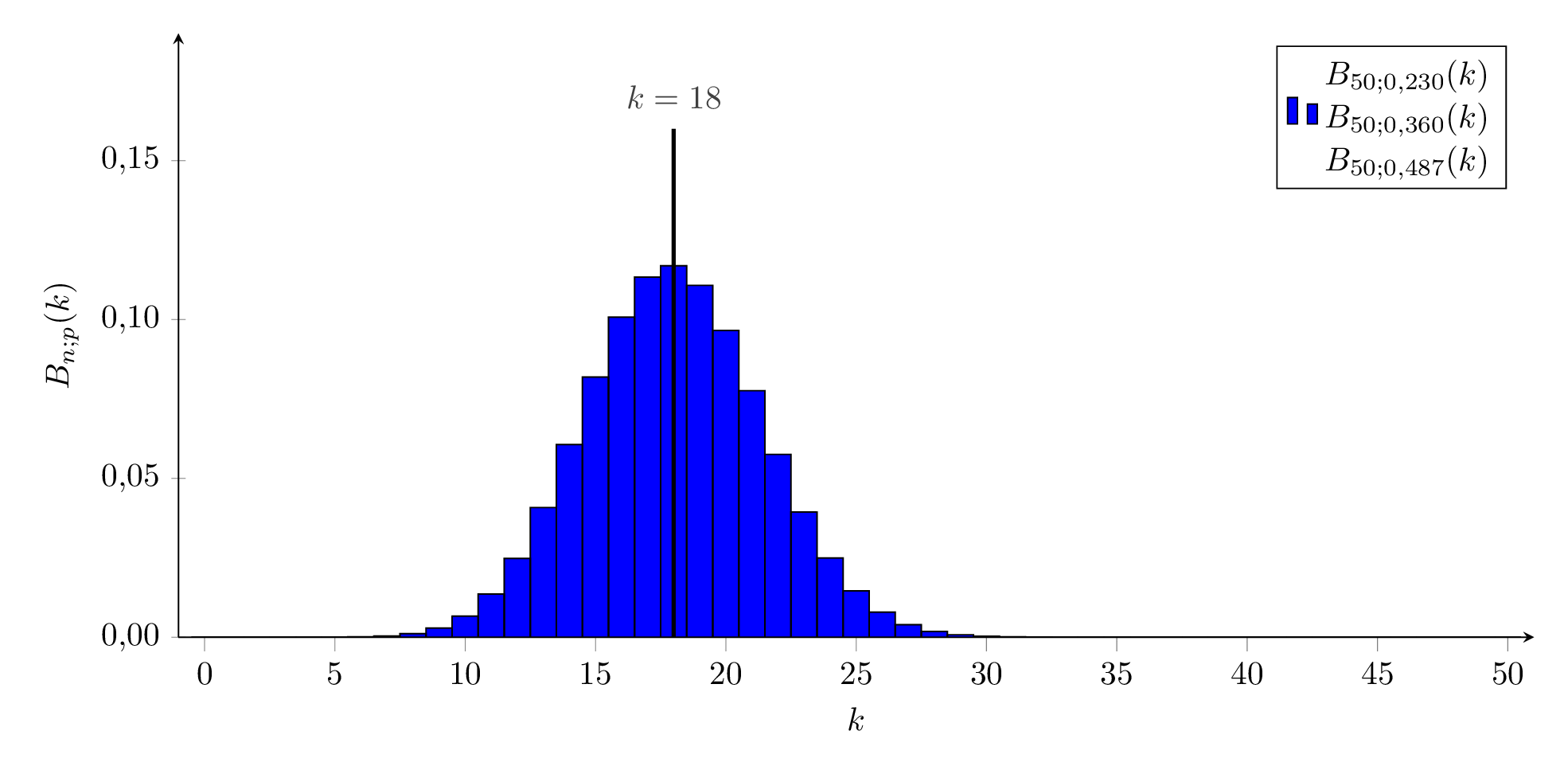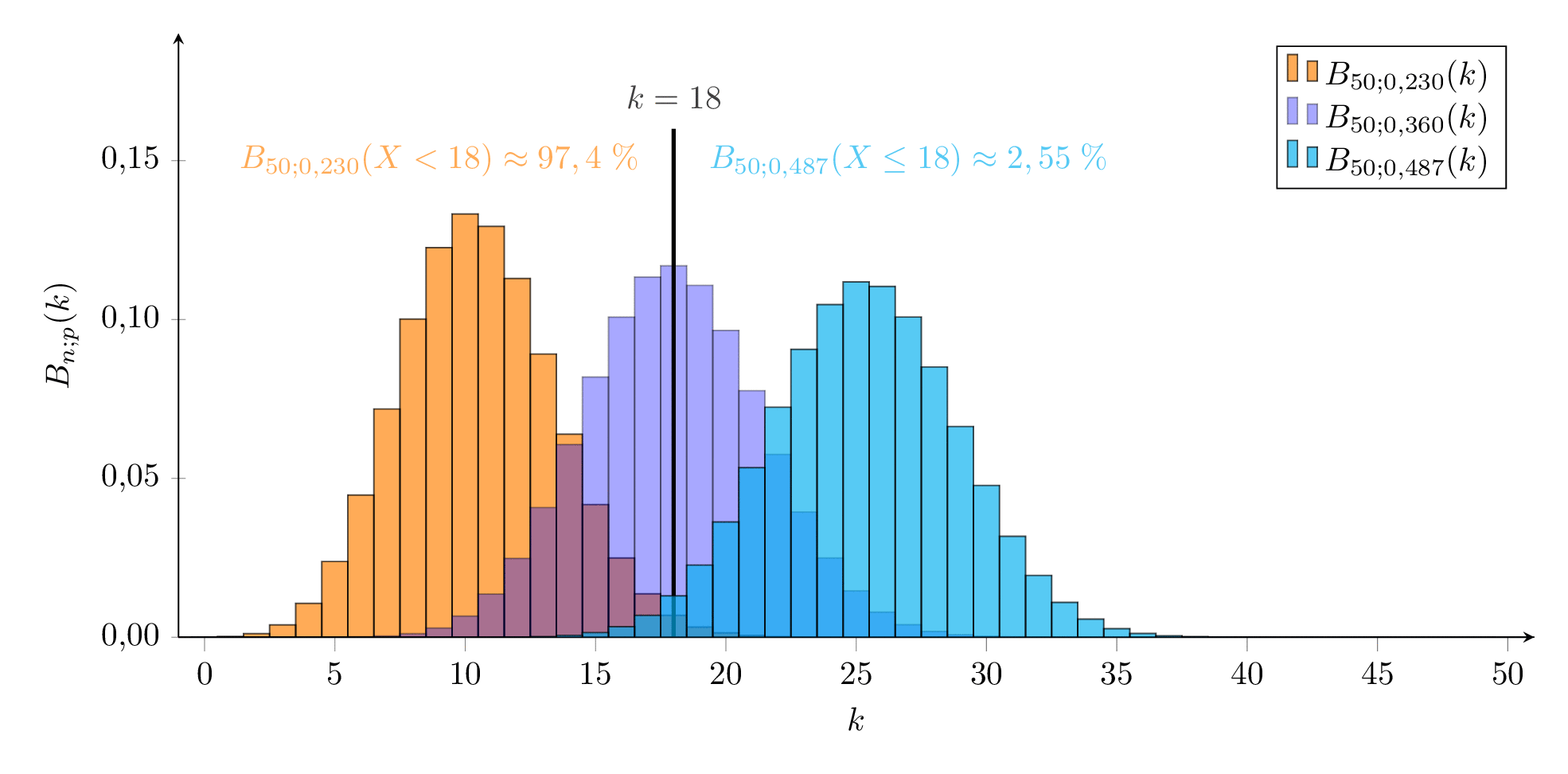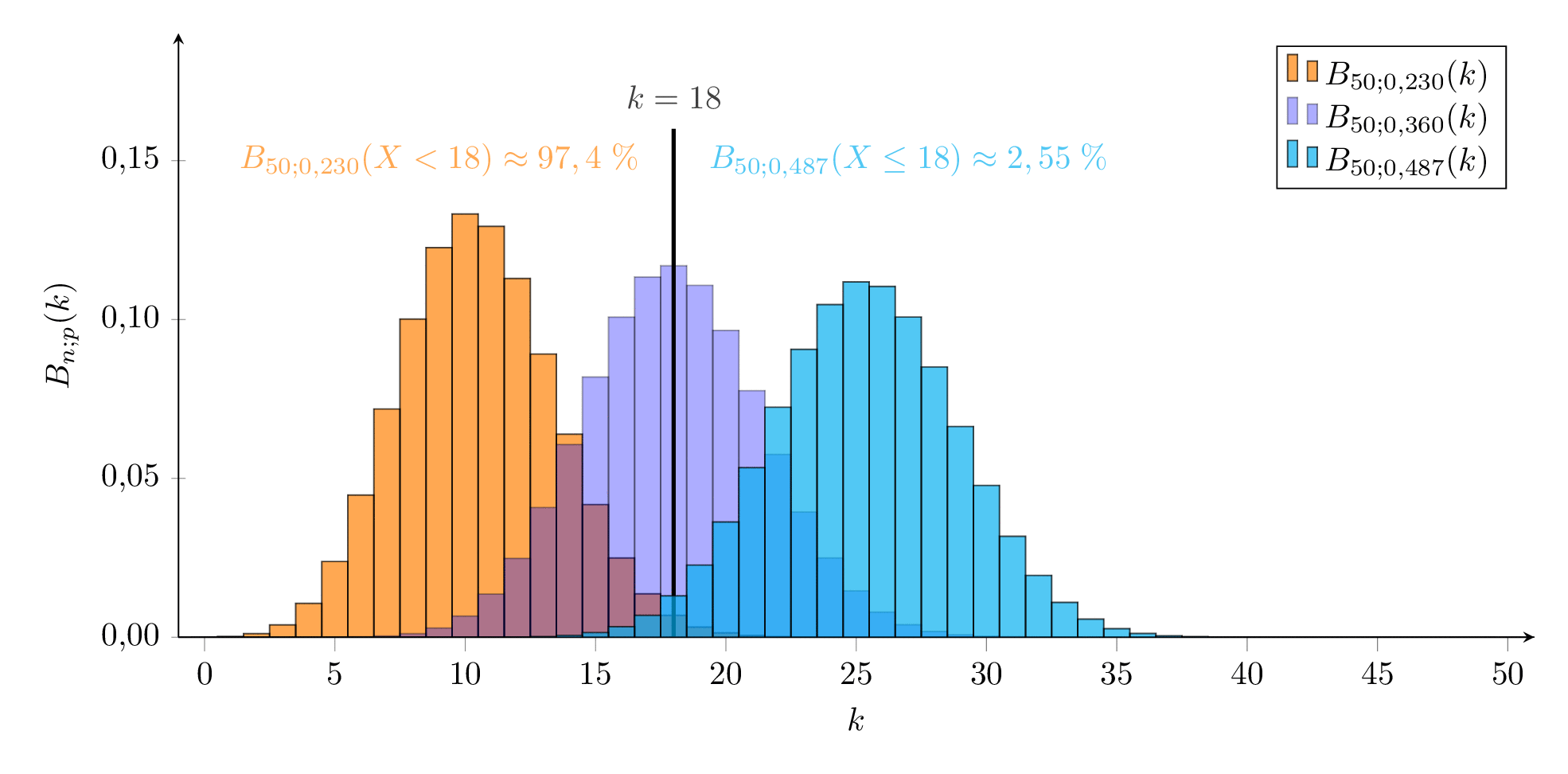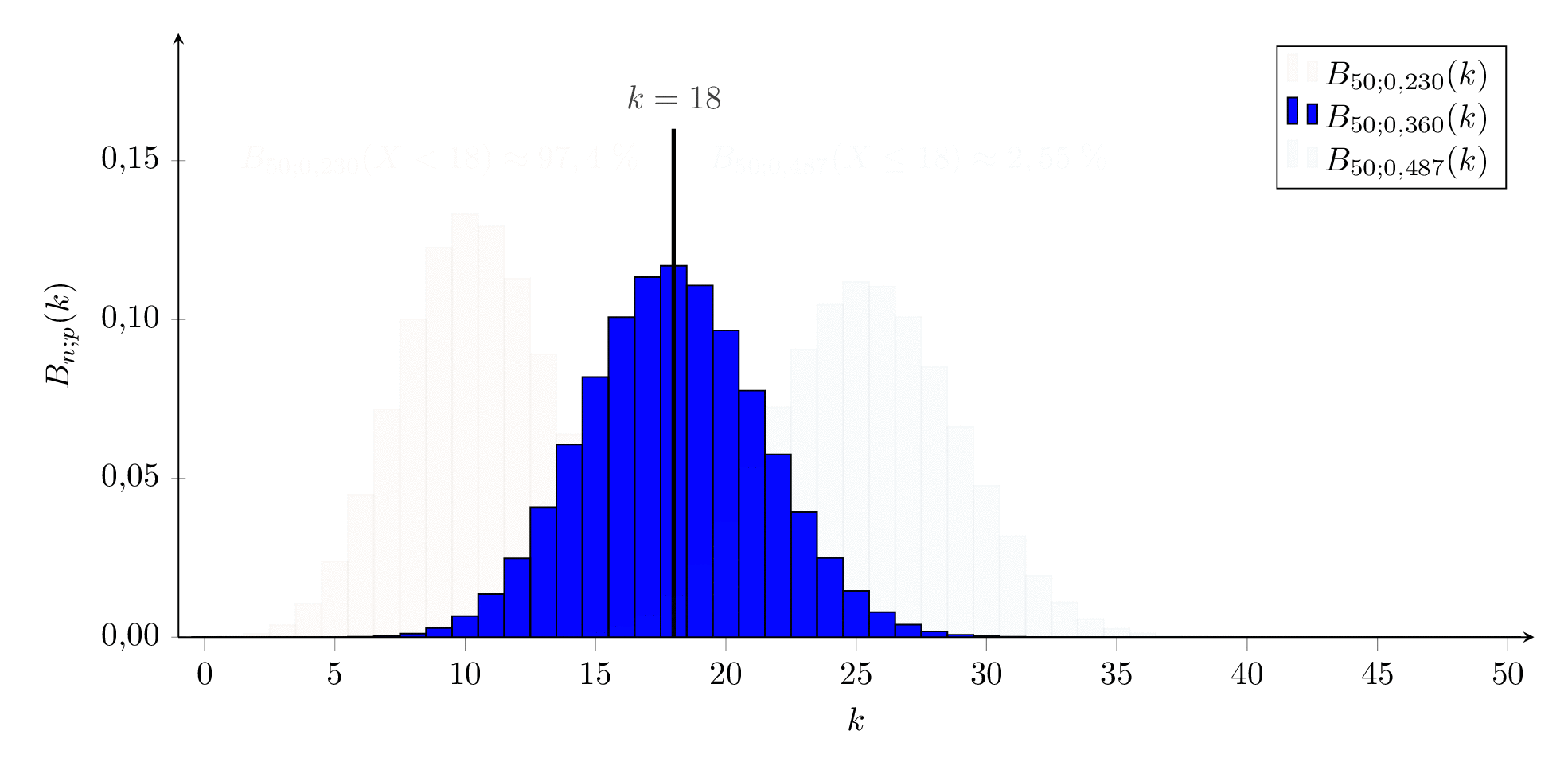
Die beobachtete relative Häufigkeit ist aber nur ein Punktschätzung für den wahren Anteil unter den Kaninchen auf der Insel. Wir suchen ein Untergrenze udn eine Obergrenze zwischen denen die beobachtete relative Häufigkeit mit -iger Wahrscheinlichkeit liegt, also zwei Binomialverteilungen an deren oberer - Grenze bzw. an deren unterer - Grenze liegt. ( bzw. deshalb, weil von den restlichen des -Intervalls die Hälfte ober- und die andere Hälfte unterhalb des Vertrauensbereichs vermutet wird).
Da die Zahlen eher gering sind, nutzen wir nicht die Näherung sondern tasten uns exakt an die Grenzen heran:
Für die Untergrenze (für ) muss gelten, dass der Ergebnisse unterhalb von 18 Kaninchen liegen, also
\[ B_{50,p_1}(X<18) \ge 97{,}5 \%
\]
ist. Lässt man sich jetzt für verschiedene Werte von kumulierte Binomialverteilungen berechnen erhält man:
| $$p_1$$ | $$F_{50, p_1}(17)$$ |
| 0,229 | 0,97516 |
| 0,230 | 0,97411 |
ist also die kleinste Wahrscheinlichkeit, bei der unsere beobachtete Anzahl an markierten Kaninchen noch im - Vertrauensintervall liegt. Dies ergibt eine Obergrenze für die Anzahl an Individuen von .
Analog suchen wir für die Obergrenze der Wahrscheinlichkeit einen Wert für so, dass die beobachtete Anzahl noch gerade im - Vertrauensintervall liegt, also
\[ B_{50,p_2}(X \le 18) \ge 2{,}5 \%
\]
Hier erhält man
| $$p_2$$ | $$F_{50, p_1}(18)$$ |
| 0,487 | 0,02554 |
| 0,488 | 0,02472 |
bzw. ist also der größte Wert für die Wahrscheinlichkeit, mit der unsere beobachtete Häufigkeit noch zu verträglich ist. Dies ergibt eine Untergrenze für die Population von .
Wir können also mit einer Wahrscheinlichkeit von davon ausgehen, dass zwischen 103 und 217 Kaninchen auf der Insel leben. Das Ergebnis scheint sehr ungenau zu sein, lässt aber immerhin eine solide Abgrenzung der Größenordnung (‘wenige Hundert’) zu.
Die beiden ‘Grenzverteilungen’ sind in der folgenden Animation orange bzw. cyan dargestellt, die mit in blau.
 Mit der Näherungsformel (deren Einsatz hier wegen der kleinen Zahl fragwürdig ist) ergibt sich für die Grenzen der Wahrscheinlichkeit
\[ \begin{align*} p_{o/u} &= h \pm c\cdot\sqrt{\frac{h(1-h)}{n}}\\[5pt]
p_{o/u} &= 0{,}360 \pm 1{,}96\cdot\sqrt{\frac{0{,}36(1-0{,}36)}{50}}\\[5pt]
p_{o/u} &\approx 0{,}360 \pm 0{,}133
\end{align*}\]
also und . In Populationszahlen bedeutet dies:
Mit der Näherungsformel (deren Einsatz hier wegen der kleinen Zahl fragwürdig ist) ergibt sich für die Grenzen der Wahrscheinlichkeit
\[ \begin{align*} p_{o/u} &= h \pm c\cdot\sqrt{\frac{h(1-h)}{n}}\\[5pt]
p_{o/u} &= 0{,}360 \pm 1{,}96\cdot\sqrt{\frac{0{,}36(1-0{,}36)}{50}}\\[5pt]
p_{o/u} &\approx 0{,}360 \pm 0{,}133
\end{align*}\]
also und . In Populationszahlen bedeutet dies:
Als Untergrenze und als Obergrenze .
Wie groß sollte die Stichprobe sein?
Wir wollen auf fünf Prozentpunkte genau ermitteln, mit welchem Ergebnis wir bei der Wahl am kommenden Sonntag (mit einer Wahrscheinlichkeit von 95 %) rechnen können. Dazu wollen wir in der Fußgängerzone eine Umfrage durchführen. Zur Planung wäre es hilfreich zu wissen, wie viele Passanten wir befragen müssen.
Nun, das 95 % -Vertrauensintervall hat eine Breite/Länge von
\[ l = 2\cdot c \cdot \sqrt{\frac{h\cdot(1-h)}{n}}
\]
also den doppelten Abstand vom Mittelwert zur 95 % - Grenze. Wir wollen das Ergebnis auf genau wissen, das Vertrauensintervall soll also höchstens breit sein.
Die obige Gleichung können wir nach dem Stichprobenumfang auflösen:
\[ n = \frac{4\cdot c^2}{l^2}\cdot h\cdot(1-h)
\]
Dies ist die Mindestanzahl an Personen, die wir fragen müssen um mit 95 %-iger Sicherheit ein Ergebnis mit einer maximalen Ungenauigkeit von zu erhalten:
\[ n \ge \frac{4\cdot c^2}{l^2}\cdot h\cdot(1-h) \quad\quad (\ast)
\]
Dummerweise haben wir noch keine Idee, wie groß unser Schätzwert (unsere Punktschätzung) ist.
Gehen wir einfach mal vom ungünstigsten Fall aus. Der Term hat ein absolutes Maximum von bei (siehe Abbildung).
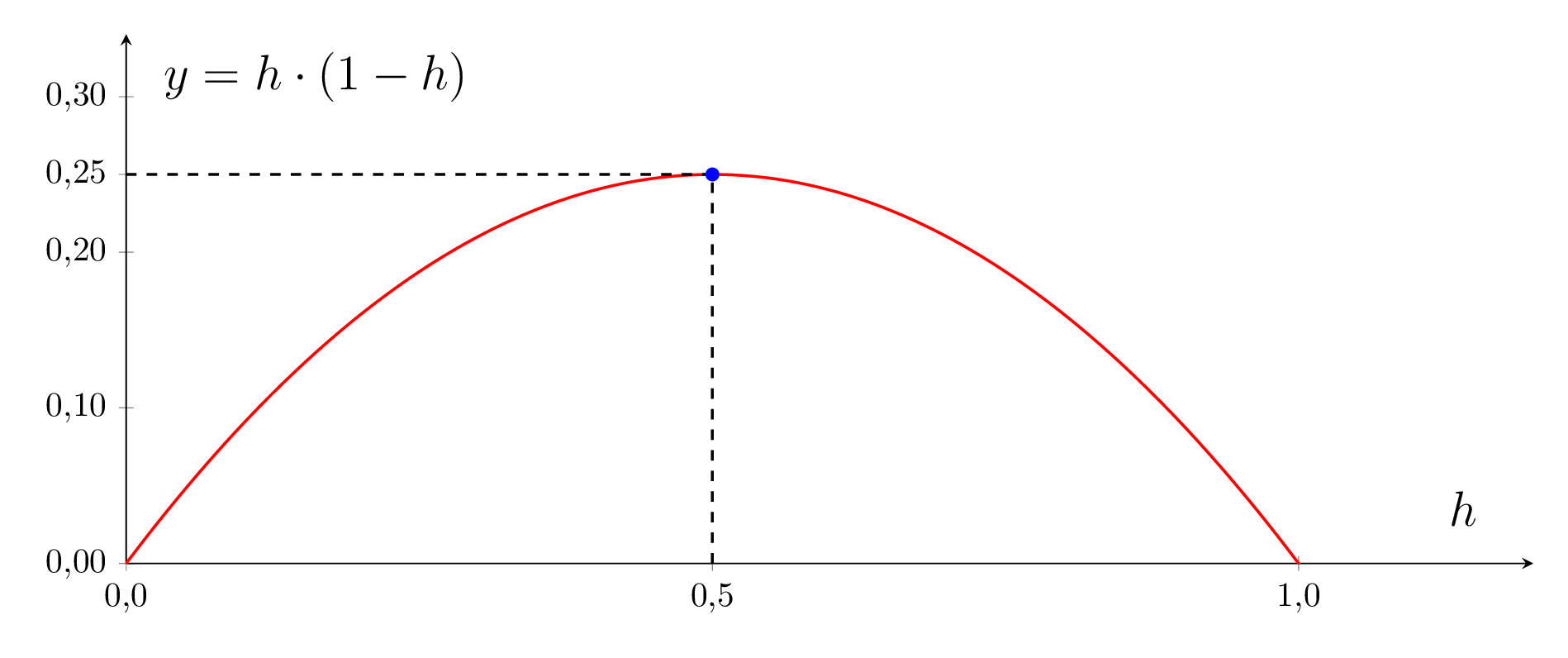 Im schlimmsten Fall müssen wir also
\[ n \ge \frac{4\cdot c^2}{l^2}\cdot 0{,}25=\frac{c^2}{l^2}
\]
Personen fragen. Da wir eine 95 %-ige Sicherheit haben wollen ist und wir wollen es auf 5 % genau haben, also und somit müssen wir
\[ n \ge \frac{1{,}96^2}{0{,}1^2} = 384{,}16
\]
also mindestens 385 Passanten befragen um mit mehr als 95 %-iger Wahrscheinlichkeit ein auf genaues Ergebnis zu erhalten.
Im schlimmsten Fall müssen wir also
\[ n \ge \frac{4\cdot c^2}{l^2}\cdot 0{,}25=\frac{c^2}{l^2}
\]
Personen fragen. Da wir eine 95 %-ige Sicherheit haben wollen ist und wir wollen es auf 5 % genau haben, also und somit müssen wir
\[ n \ge \frac{1{,}96^2}{0{,}1^2} = 384{,}16
\]
also mindestens 385 Passanten befragen um mit mehr als 95 %-iger Wahrscheinlichkeit ein auf genaues Ergebnis zu erhalten.
Wenn wir davon ausgehen können, dass wir ca. 20 % der Stimmen bekommen, unsere Punktschätzung also 0,2 ist, dann können wir direkt die obige Formel nutzen
\[ \begin{align*} n & \ge \frac{4\cdot c^2}{l^2}\cdot h \cdot(1-h) \\[5pt]
n & \ge \frac{4\cdot 1{,}96^2}{0{,}1^2}\cdot 0{,}2\cdot(1-0{,}2) \approx 245{,}9
\end{align*}
\]
und müssen “nur” 246 Passanten befragen, um die gleiche Genauigkeit zu erhalten.